Why doesn't my chat bot know who my dog is?


I had a really interesting observation when testing the Chatlie chatbot on my portfolio website. I have some specific easter eggs in the knowledge base that should be retrieved, but there was one question that the model would never know the answer to "Who is Remi?"
Remi is my dog, and despite Chatlie not knowing who he is, there is a blurb in the easter egg about him that shows up in the knowledge content chunks for my Chatlie model:
In January 2026, we adopted a dog, Remi. He is an 8 year old Great Dane/Labrador mix. He is extremely playful and loving, and has become a welcome addition to our family. We consider it his retirement home, and have enjoyed giving him a calm environment and learning more about dog ownership by attending obedience classes.
I ended up having a lot of fun investigating this issue and so wanted to share what was found and what was done to remediate.
The Problem
The way RAGs work is to get the knowledge from the vector DB as an evolving and persistent source of knowledge and enable an LLM to generate responses based on that knowledge. Any message flagged as "Unanswered" means that the generator LLM did not have enough knowledge provided to generate the solution. So let's look at the knowledge that was given:
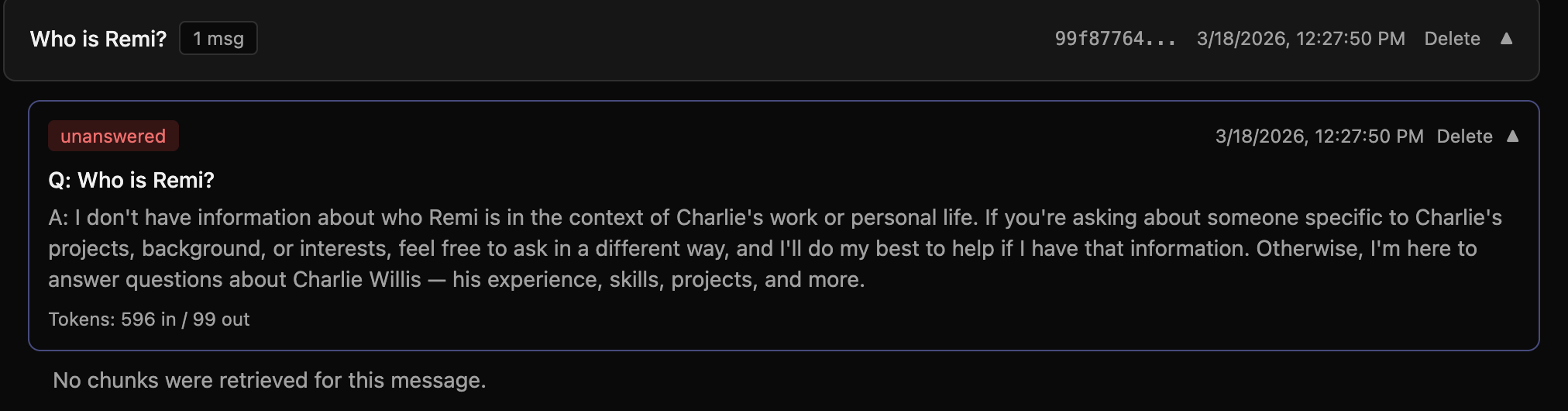
No chunks were retrieved for this message. No way for the LLM to know who Remi is. Let's find the chunk in content and run a query and see what the similarity threshold would have to be to find the content chunk about Remi.
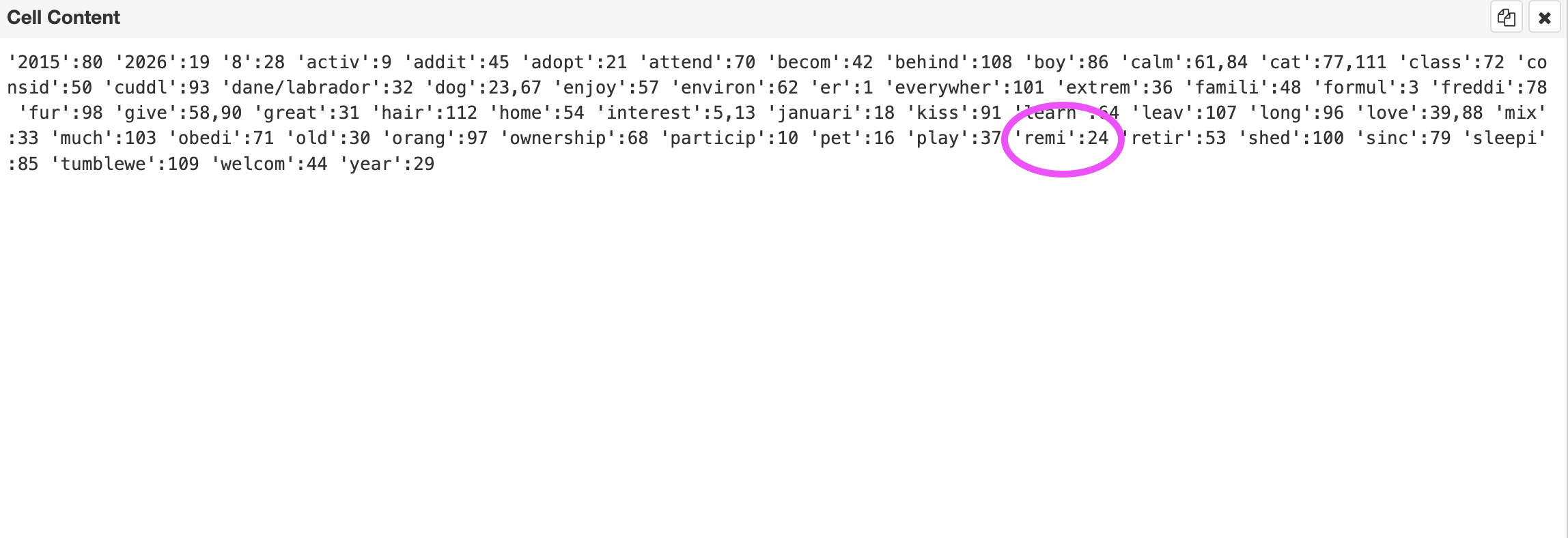
First we'll find the chunk with the Remi information with this query, which returned 908
SELECT id, content
FROM content_chunks
WHERE model_id = (SELECT id FROM rag_models WHERE slug = 'chatlie')
AND content ILIKE '%remi%';
Then we'll embed the query, which will give a 1024 length vector
curl -s https://api.voyageai.com/v1/embeddings \
-H "Authorization: Bearer $VOYAGE_API_KEY" \
-H "Content-Type: application/json" \
-d '{"input": ["Who is Remi?"], "model": "voyage-4-lite"}' \
| jq -c '.data[0].embedding'And lastly, query against that vector
SELECT
id,
LEFT(content, 200) AS preview,
ROUND((embedding <=> '[{MASSIVE_VECTOR}]')::numeric, 4) AS cosine_distance,
ROUND((1.0 - (embedding <=> '[{MASSIVE_VECTOR}]'))::numeric, 4) AS similarity_threshold_needed
FROM content_chunks
WHERE id = 908;
And then I saw the issue:
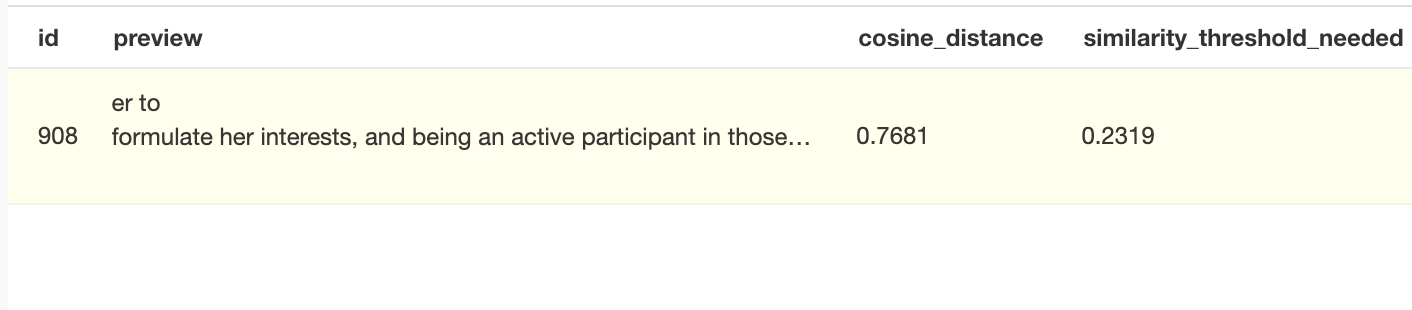
The Anti-Solution
OK so the solution is easy, right? I can just drop the similarity to <= .2319 and hooray the model knows who Remi is!
Since I changed a tuning parameter though, I wanted to regression test. First with an off topic question. And I saw the downside of tuning to this low of a similarity index, why this "solution" is an anti solution. 8 chunks pulled in similar to "What's the weather like today?"
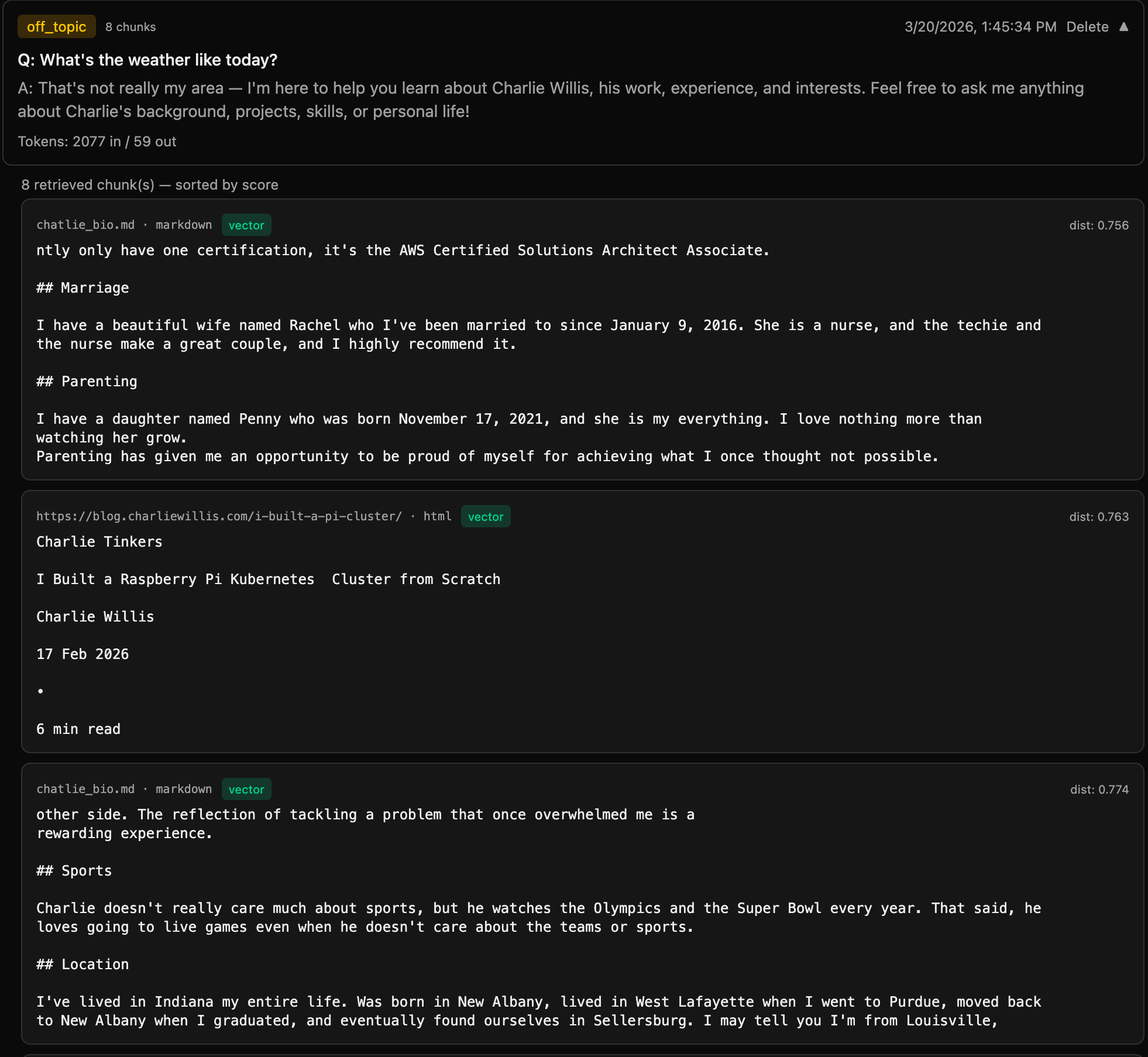
Instead of when the model was properly tuned there were no chunks that came in!
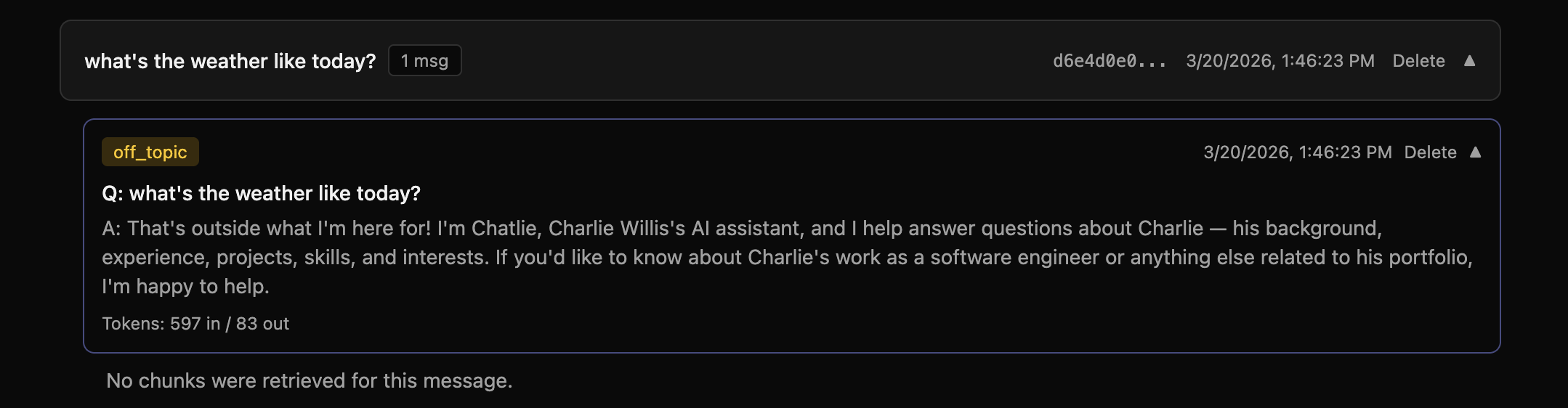
This might not seem like a big deal, but it actually defeats the whole purpose of RAG. One thing I love RAG for is keeping a slim context. When RAGr gets irrelevant context there is an increased risk our models overshare, hallucinate, consume more tokens, and even see slow response times. So UX is worse, cost goes up, and one of the benefits of RAG are negated.
The Solution
So what is the real solution? Let's go back to the query where I found the right chunk
SELECT id, content
FROM content_chunks
WHERE model_id = (SELECT id FROM rag_models WHERE slug = 'chatlie')
AND content ILIKE '%remi%';That made the response come up perfectly. Just by scanning for the word "Remi".
So one option for remediation is I could just have a rudimentary query "give me the chunks with the cosine distance under the similarity threshold and also any chunk that contains the word." And with the reranker, that would probably work. But what about times where it's not really a word match? If I worked on a a premium product, or I made a really cool song remix, we'd get those irrelevant chunks. I end up in the same boat. I also have to check it for every word in the query, and words like "is" polluting the relevant chunks. Then I have to maintain a blocklist of words to ignore, and of course I'll miss some, and then all of the sudden I am in the same spot. Surely there's some better way to do this that isn't too complicated?
That's when I found out Postgres has this brilliance right out of the box for us with a full-text search feature. Not only does it find "Remi" as a distinct token (so 'premium' and 'reminder' don't pollute the relevant results the way ILIKE would), it also ranks chunks by how often the term appears. And the blocklist concern? No problem, Postgres handles it with stop words, "is", "the", "what", etc. are all stripped in the full text search. In addition, plurality and tense are irrelevant, "running", "runs", and "run" appearing in the same search count as 3 instances of the word "run".
Merging
OK so now we've got keyword search in RAGr, and that's great. From there there were a few options. The simplest was, I could allow models to specify if they want vector search or keyword search, there are strengths to either one, and some models may perform just fine with one or the other. Or I could just send all the results from vector and all the results from keyword search to the reranker, but then RAGr needs to have reranker always enabled (more cost and it loses a configuration for the model maintainers). Or there's my third and favorite option Reciprocal Rank Fusion (RRF). A near-perfect solution to what I want, I can combine multiple chunk retrieval methods, and rank them together based on the position they are in their respective received chunks. Chunks in both retrieval methods score highest, followed by the highest scoring chunks from each list.
RAGr takes the top 60 chunks (configurable per model) into RRF, optionally send the RRF output to the reranker, and then trim it down to the top K (also configurable per model).
But wait...
OK great RAGr has a merged result, it reranks it, and only sending the best knowledge to the generator, right? Well let's check that off-topic example again and see.
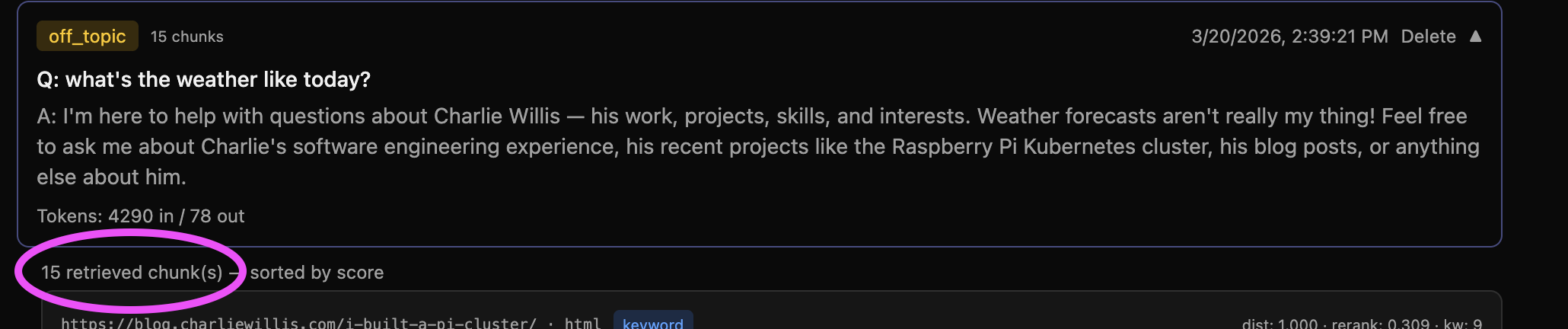
Yep, 15 chunks go to the generator, all of them found with the keyword search. Maybe it's "like" because I have the word like in some chunks, maybe it's "today", but I know there's nothing about weather in my knowledge base. The good news is, in the screenshot also lies the answer. The rerank score: .309. OK, that's hot garbage knowledge. So what do I do?
Post-Rerank Threshold
I couldn't let all this work on keyword search go to waste if it was going to be worse than the lousy tuning parameters above that brought in 8 chunks. So what's the solution? A new RAGr feature, the post-rerank threshold. Now RAGr users can configure a minimum rerank score after reranking to remove irrelevant knowledge altogether. This value is configurable, 0 turning it off altogether. In this example, there was an 86% reduction in token usage with a .35 rerank minimum.

Result
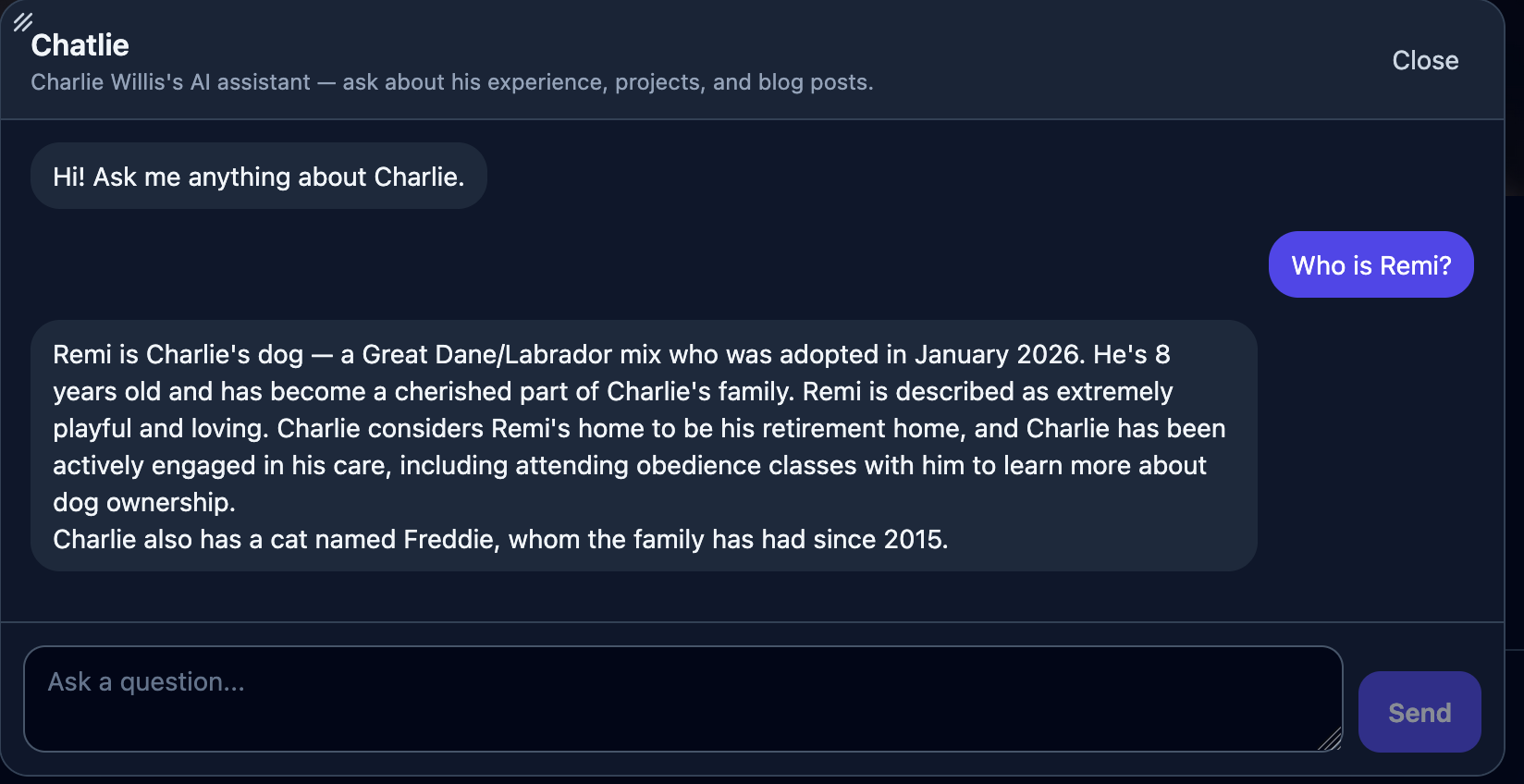
Chatlie knows who Remi is, and RAGr now has a gap resolved. Model maintainers can tune retrieval based on vectors, and let keyword search handle these specific cases.
I hardened the RAGr platform against a common type of retrieval failure. RAGr now gives the generator a better knowledge base with more relevant chunks than ever before. And most importantly, I got to show off a picture of my dog for this blog post, and people can ask about him on my website.